🤖 ai
LLMs Get Brain Boost: DeepMind's Evo-Memory for Smarter AI
Google DeepMind and U of I researchers developed Evo-Memory & ReMem, helping LLM agents truly learn from past experiences, not just replay them.
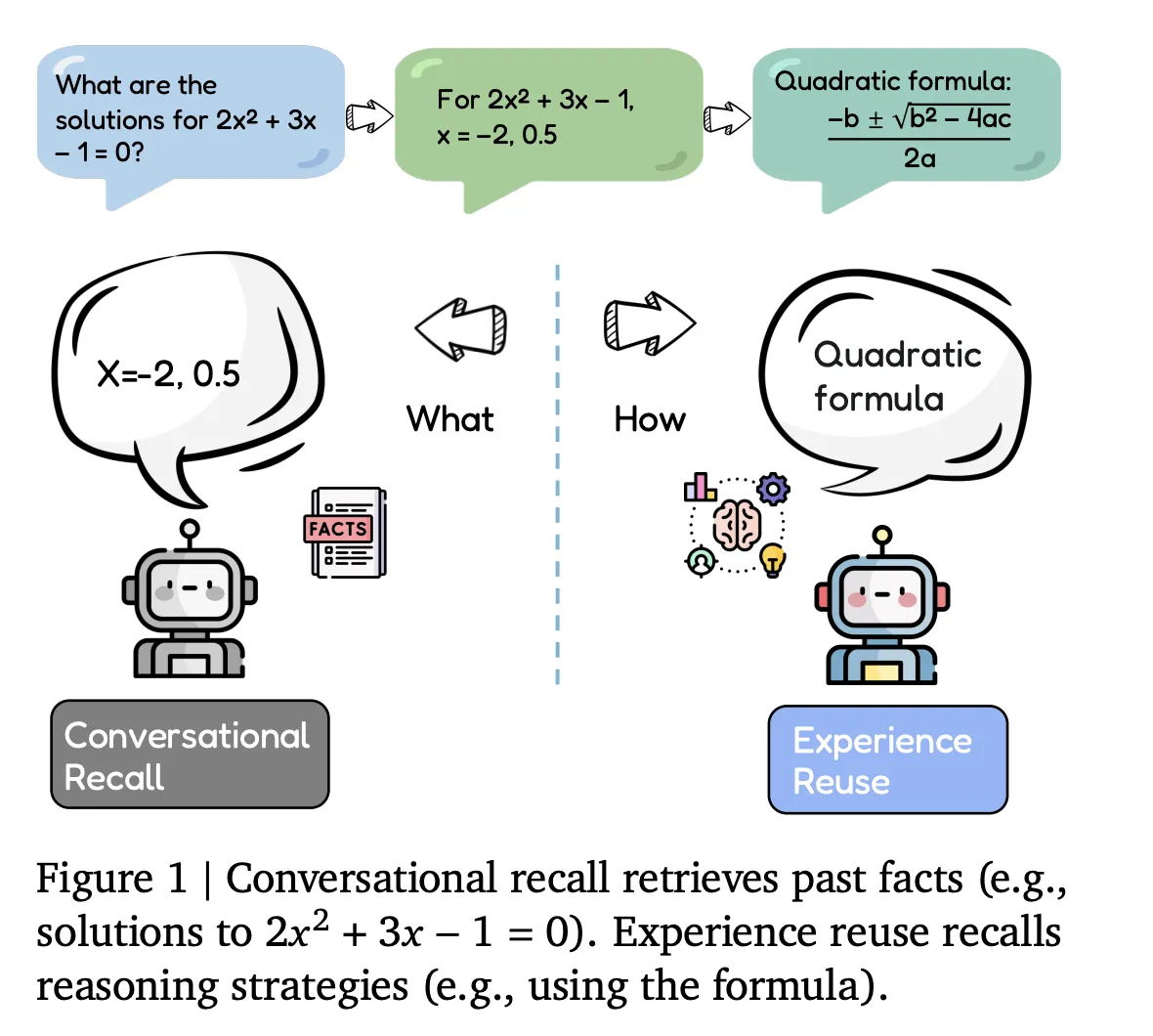
What’s Happening Ever wonder if your large language model (LLM) agent is truly learning from its past interactions, or just pulling up old notes? Researchers from Google DeepMind and the University of Illinois Urbana-Champaign have identified a crucial gap in how LLM agents handle stored information. They’ve observed that while agents can ‘store everything they see,’ they often struggle to ‘improve their policies at test time’ using those experiences. Instead, they typically just ‘replay context windows,’ meaning they recall information without deeply integrating it to refine their future actions. This is a significant hurdle. It means an agent might remember every step of a failed attempt but not actually internalize why it failed to devise a better strategy for next time. To address this, the teams have introduced Evo-Memory, a new streaming benchmark, and the ReMem framework. These tools are specifically designed to evaluate and enable LLM agents to genuinely learn and adapt from their accumulated experiences, rather than just passively retrieving them. ## Why This Matters This isn’t just a technical tweak; it’s a fundamental shift in how we expect AI agents to evolve. Current LLMs are incredible at generating text and processing information, but their ability to truly ‘learn’ from their own operational history has been surprisingly limited. Imagine an agent that, after several failed attempts to solve a complex problem, doesn’t just try the same approach again with slightly different wording. Instead, it would analyze its past failures, understand the underlying reasons, and actively develop a superior strategy for the next try. Evo-Memory and ReMem pave the way for LLM agents that can continuously refine their decision-making processes and ‘policies.’ This means agents that are not only knowledgeable but also increasingly competent, efficient, and reliable over extended periods. The ability for an AI to actually improve its behavior based on experience, much like a human or an animal, is a critical step towards more autonomous and effective AI systems. It moves beyond mere recall to genuine intelligence. - More Adaptive AI: Agents will better understand context and user intent based on cumulative interactions.
- Reduced Repetition: Less likelihood of agents giving similar, ineffective responses to recurring problems.
- Personalized Experiences: AI systems could tailor their approach more precisely to individual users’ evolving needs.
- Faster AI Development: Researchers will have a standardized way to measure and accelerate agent learning capabilities. ## The Bottom Line The introduction of Evo-Memory and ReMem marks a significant stride toward creating truly intelligent, self-improving LLM agents. It moves us closer to a future where AI doesn’t just process information, but actively becomes wiser with every interaction. This could unlock a new era of AI applications, from more intuitive personal assistants to highly specialized problem-solvers across various industries. Will this focus on ‘experience reuse’ finally bridge the gap between AI memory and true AI learning?
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


