NVIDIA and the University of Maryland Researchers dropped...
Understanding audio has always been the multimodal frontier that lags behind vision.
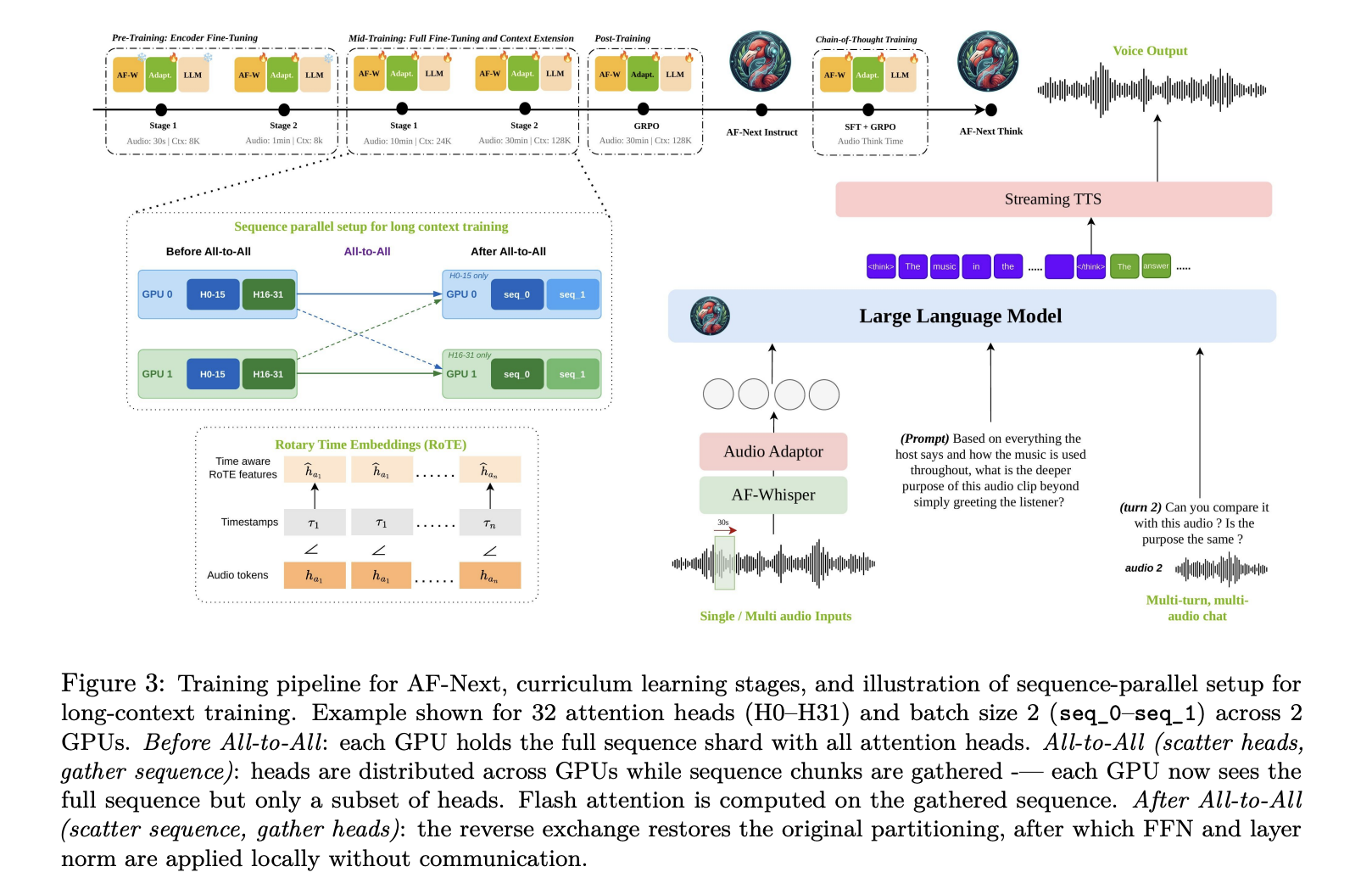
What’s Happening
Alright so Understanding audio has always been the multimodal frontier that lags behind vision.
While image-language models have rapidly scaled toward real-world deployment, building open models that robustly reason over speech, environmental sounds, and music — especially at length — has remained quite hard. (yes, really)
NVIDIA and the University of Maryland researchers are now taking a direct swing [] The post NVIDIA and the University of Maryland Researchers dropped Audio Flamingo Next (AF-Next): A Super Pow Understanding audio has always been the multimodal frontier that lags behind vision.
Why This Matters
The AI space continues to evolve at a wild pace, with developments like this becoming more common.
This adds to the ongoing AI race that’s captivating the tech world.
The Bottom Line
This story is still developing, and we’ll keep you updated as more info drops.
We want to hear your thoughts on this.
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


