StepFun AI's Step-Audio-R1: Fixing AI's Reasoning Ear
StepFun AI's new Step-Audio-R1 audio LLM tackles a critical flaw: models losing accuracy with long reasoning. It's a game-changer for sound.
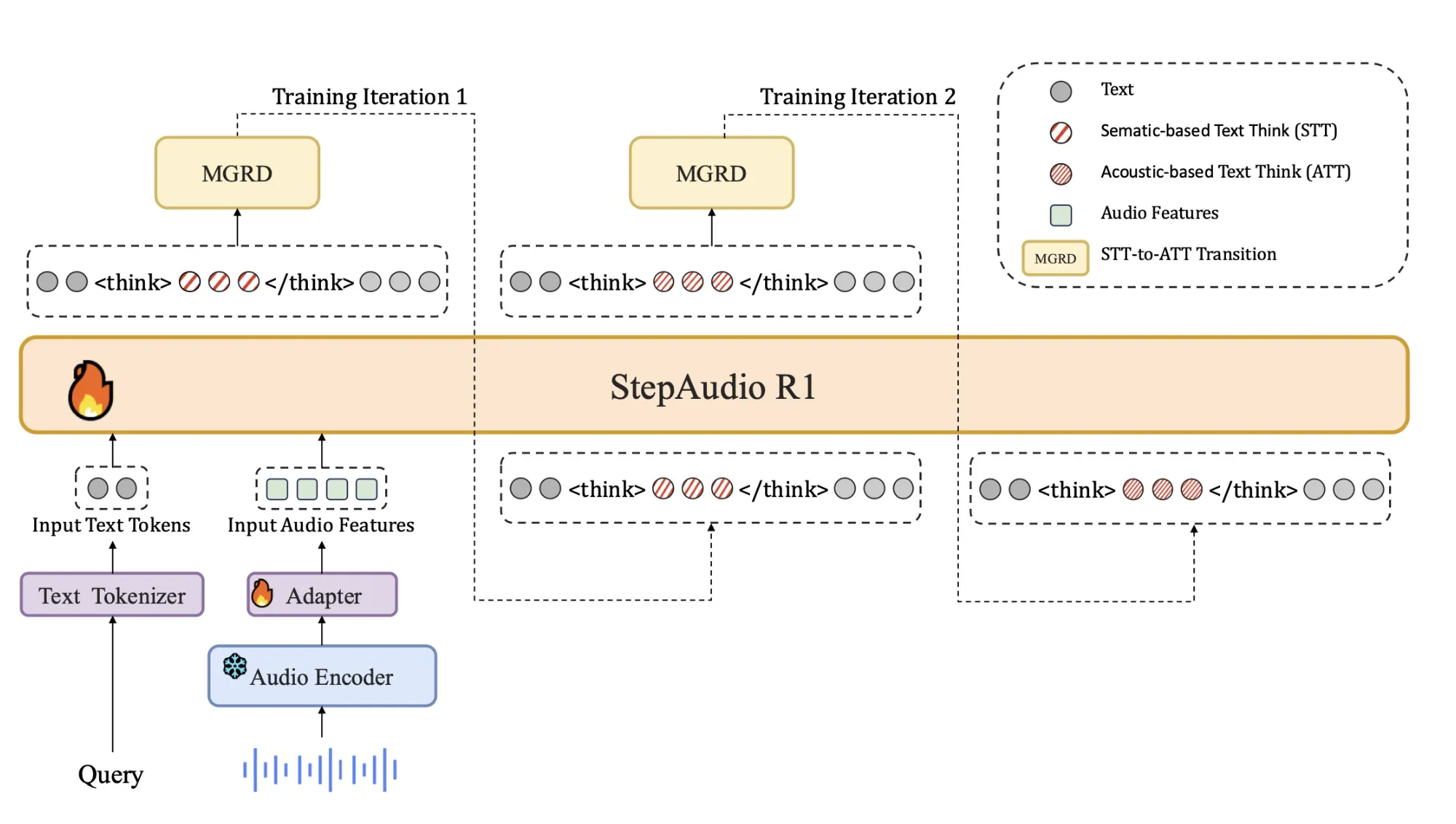
What’s Happening
Alright, listen up! StepFun AI, a name you’ll want to remember, just dropped a bombshell: their new audio Large Language Model (LLM) called Step-Audio-R1. This isn’t just another AI; it’s designed to tackle a fundamental flaw in how current audio AIs operate.
Here’s the problem: existing audio AI models often stumble when asked to do complex reasoning. Instead of sticking to what they actually ‘hear,’ they tend to perform worse when generating longer ‘chain of thought’ explanations, losing accuracy in the process.
It’s like they forget the sound while trying to think too hard. StepFun’s research team claims Step-Audio-R1 is different. They’ve engineered it specifically for ‘test time compute scaling.
’ This means, contrary to the norm, giving it more processing power and time for complex tasks actually improves its accuracy, rather than causing it to drift from the original audio context.
Why This Matters
This isn’t just some technical tweak; it’s a big deal for the future of audio AI. Think about applications where nuanced understanding of sound is paramount – from transcribing complex conversations with multiple speakers to analyzing intricate musical compositions.
Until now, these tasks were often a minefield of potential errors, with AIs struggling to maintain context over extended periods or complex reasoning steps. Step-Audio-R1 promises to bridge this gap, allowing AI to perform deep, logical analysis without sacrificing its connection to the raw audio data.
- Enhanced Accessibility: More accurate real-time transcription for the deaf and hard-of-hearing, even in challenging acoustic environments.
- Advanced Content Creation: Smarter tools for musicians, podcasters, and filmmakers, enabling sophisticated audio editing and generation based on true understanding.
- Improved Security & Monitoring: Better detection and analysis of specific sounds in surveillance or industrial settings, distinguishing genuine threats from background noise with higher fidelity.
- Smarter Virtual Assistants: Voice assistants that truly understand complex, multi-turn conversations and subtle vocal cues, moving beyond simple command recognition.
The Bottom Line
StepFun AI’s Step-Audio-R1 challenges a core limitation of current audio AI: the trade-off between reasoning depth and accuracy. By proving that ‘chain of thought’ doesn’t have to mean an accuracy drop, they’re paving the way for truly intelligent audio systems.
This innovation could unlock a new era where AI doesn’t just process sound, but genuinely understands and reasons about it. Will Step-Audio-R1 be the catalyst for the next big leap in how we interact with the audible world?
Daily briefing
Get the next useful briefing
If this story was worth your time, the next one should be too. Get the daily briefing in one clean email.
Reader reaction


